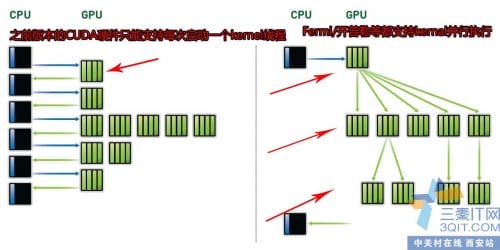
自从NV开放 4GB版本的GTX680之后,所有游戏都阻止不了GTX680了。除了游戏,我们还有什么点子可以发挥这块单芯片神卡的威力呢?没错,就是通用运算技术CUDA!高性能运算,复杂的物理运算和人工智能仿真等等的如果只用CPU运行,估计6核的Ivy Bridge也够呛的了。即使启动了超线程技术,也只能硬件上实现12线程。对于动辄上千ALU的GPU来说,这只能是小菜一碟。另外,还有一个巨大的线程切换差异,就是说CPU多线程切换需要上千时钟周期,而GPU则只需要个位数的时钟周期。
这就为什么GPU隐藏着巨大的能量。NVIDIA很聪明地看到了这块市场的契机。Fermi的设计首创性地加入了和处理器一样的统一读写二级缓存,随后GK104更把底层的SMX进行变革。下面我们通过技术宅男玩家为我们展开一场奇幻的CUDA旅行。当然,主角是当下性能极其强悍的GTX680 4GB。

据说,技术宅的厕纸用完了之后就会用书本。

技术宅受到刺激后,迷上了超大规模程序设计,那个叫什么CUDA神秘兮兮的东西。

平台艳照

那个神秘兮兮的CUDA的环境配置。1安装CUDA工具箱,第二步安装显卡驱动,第三步安装CUDA SDK。前两步必不可少,第三步可以缺省。
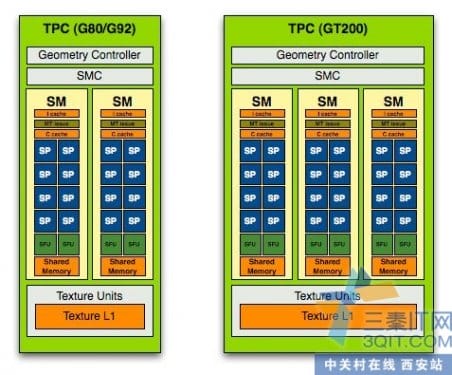
技术宅帮我们复习一下,G80和GT200的SM架构。这种差异导致了CUDA程序上的不同优化。
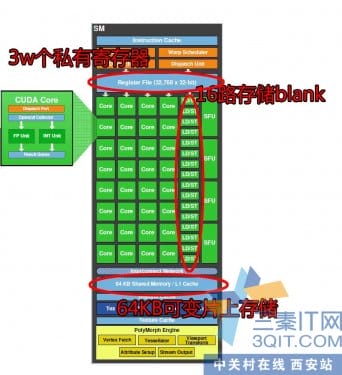
好了,老架构的不花时间去讨论,直奔最近在通用计算大放异彩的费米架构。技术宅说它革命性地加入了读写统一的1,2级缓存。亲,这是模仿CPU的设计吗?下面结合硬件来说说CUDA是如何根据它来优化。SM拥有3万个高速寄存器!天哪,8核CPU的不过百的寄存器情何以堪!难怪线程切换的速度如此之快。16路高速存储通道来并行操作64KB的片上高速缓存,速度达到1TB/s的级别!!!!!!
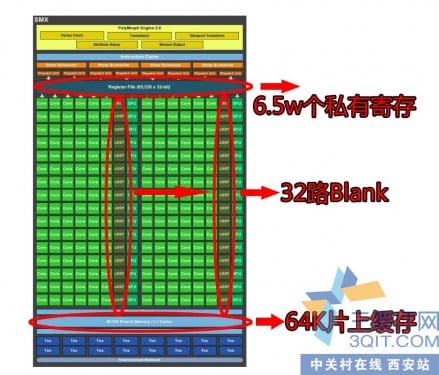
开普勒再度加强,在晶体管数量控制在30亿的情况下竟然设计出比费米多100%的CUDA核心。从SMX架构上可以到处,要以往 CUDA程序为开普勒优化,首要任务是让block里面的线程尽量地多。GT200 SM允许活动线程是1024个,费米优化的代码可以增加到1536个线程,而开普勒更爆增到2048个活动线程(注:规格上和GK110一样)。
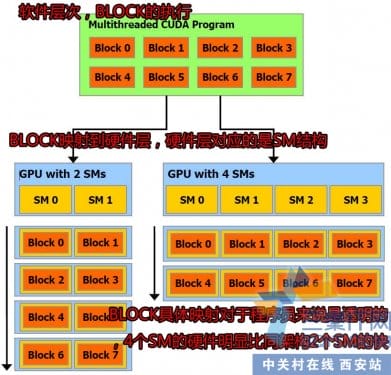
这个是软件层次对应的硬件层次。BLOCK编程上的线程块,它们是分时在SM里运行,一个CUDA程序会有多个blcok并行运行,而每个block就是说线程块又包含了舒数十到上百的线程组成。也就构成了CUDA。
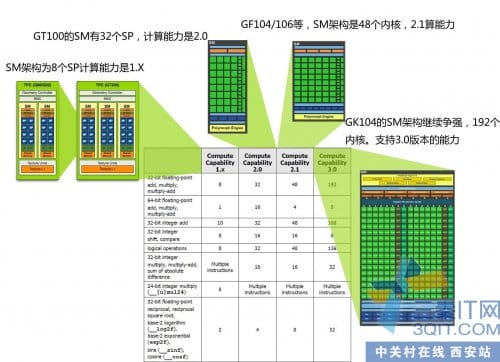
架构的不同对应不同的计算规格。3代运算架构,对用不同的支持。代码优化可以适当对不同特征进行优化。譬如开普勒等硬件可以支持更大的block内部线程,因此可以支持更多的线程进行片上的同步工作。另外譬如Fermi和开普勒有DRAM缓存,所以对DRAM优化的力度没有G80那么吃力。