
【CSDN现场报道中国IT界技术盛会——Hadoop与大数据技术大会(Hadoop&BigData Technology Conference 2012,HBTC 2012)于2012年11月30日-12月1日在北京新云南皇冠假日酒店隆重召开。本次大会以“大数据共享与开放技术”为主题,聚焦于Hadoop与大 数据,力邀数十位国内外Hadoop及大数据技术应用的产学界人士和实践企业,探讨大数据技术生态系统的现状和发展趋势,并围绕Hadoop与大数据热点 技术和应用实践进行深入解析。
IBM中国研究院信息管理与医疗降首席科学家潘越,他阐述了大数据的4个V:大数据首先代表的是数据产生的量比传统的量大很多,他认为传统的G级别或者T级别的数据存储和管理的方案,目前看起来都不太合适或者是性价比不高。第二个V是针对机器产生的数据,传统的分析的周期原来可能都是以月、周、天这样的时间来做分析的,现在很多的分析都需要实时的决策,所以数据关键是速度。第三个V当然是涉及到用户数据的多样性。在IBM研究部门还提出来第四个V,数据里包含的不确定性。数据的不确定性和数据的多样性之间可能也有一种天然的联系,但是也不完全地等同。然后得出了三点结论:1.大数据并不能固守在自己的领域里面,要跟企业中其他的数据管理、信息分析结合起来。2.在大数据的部署过程中会采用很多种的技术,我们不仅要看到技术的有效性,还要更多地考虑一下:如果把技术结合在一起,会产生什么样的价值。3.像大数据这样的平台应该是一个共享的平台,应该能为大家创造一个共同协作的环境,这样就能降低成本和风险。

IBM中国研究院信息管理与医疗降首席科学家 潘越
以下是演讲实录:
首先非常感谢大家给我这个机会分享我个人对大数据的看法。对于企业来讲,应该如何使用大数据来获取最大的价值。
我们引用了一个Gartner的数据,我们是用大数据还是BigIIIusion。调查的问题是大数据对企业来说是否有价值,大数据的项目是不是一个成功的项目。大家可以看到大概有不到1/5的企业的CIO很确定大数据对他来讲是一个有价值的投资,并且已经看到了效果。更多还是处于不确定或者是观望要不要投资的阶段,因此我很欣赏这一点,大数据或者是小数据还是数据,既然是数据对一个企业来讲就要涉及到数据怎么去管理,怎么样去利用数据产生商业的价值的问题。所以,我们要放在这样的一个上下文里面来理解大数据和理解大数据的技术。
如果我们看大数据和传统的数据有什么不同,一般来讲有两类的数据,一类是像左边提到的一些用户产生的数据,主要是在社交媒体还有一些用户的活动产生的数据。第二类是机器产生的数据,包括了RFID的设备,IPS的设备,各种各样的智能水表、电表、气表,还有因为智能手机的采用,很多的影像数据,这些都是机器产生的数据。为了理解这些数据有什么价值和特点,我们可以把数据放在企业管理的框架下来看。传统的企业管理侧重于商业流程产生的数据上,比如说用户的信息、市场的信息、产品的信息还有供应链的信息等。刚才讲到的用户产生的数据和机器产生的数据,看到也是在很多商业活动的边缘产生的,可能不见得是传统的商业活动,可能是通过电商的方法来产生的一些在线的数据,可能是通过物联网的手段扩展它的信息采集点产生的数据。所以,它是扩展原来的商业活动的范围。同时,他们有不同的特点。像机器产生的数据实时性要求就会比较高。像用户产生的数据有很多是文本、图像、影像。
大数据的4个V
我们看来需要把这两类数据和无原有的数据结合起来,之后在一起产生商业智能分析,通过这样的过程让这些数据来产生它的价值。所以刚才就提到了数据的几个类型,我想这几个V,前三个V对大家来说都比较熟悉。大数据首先代表的是数据产生的量比传统的量大很多,以至于说传统的G级别的或者是T级别的数据存储和管理的方案目前看起来都不太合适,或者是性价比不够好。第二个V是针对机器产生的数据,传统的分析的周期原来可能都是以月、周、天这样的时间来做分析的,现在有很多的分析需要做一些实时的决策。所以这些数据关键是速度。
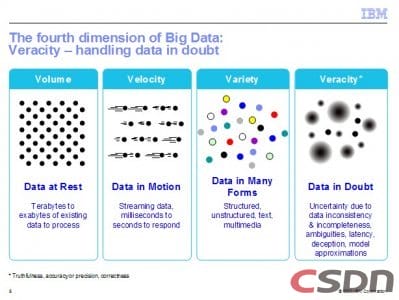
第三个V当然是涉及到用户数据的多样性。在IBM研究部门我们还提出来第四个V,就是这种数据里面包含的不确定性。当然你要讲的话,数据的不确定性和数据的多样性之间可能也有一种天然的联系。但是也不完全地等同,一般来讲用户产生的数据这些文本数据本身包含着一些歧义和模糊所以有很多的不确定性,机器产生的数据我们也不能当成不确定性,因为测量的过程中还会产生很多的误差,所以有很多的不确定性。针对不确定性,以前都是在分别不同的分析模块里处理,我们现在单独提出来不确定性可能需要有一些共用的技术来对他进行处理。
IBM是一个传统的厂商,有什么样的经验去处理大数据,我想我们可能从某一个角度来看,在过去的研究活动中也处理了大量的复杂的数据。大家可能有的人知道Watson系统,这是一个自动问答的系统,在2011年智力问答的节目中战胜了人类选手。这是人工智能的里程碑,它凭借什么取得了这样的结果,它后面是有很多的非结构化文本的分析和处理。可以和原来的专家系统和其他系统的区别就在于它的知识获取的能力。所以可以处理维基百科、大英百科全书和IMDP等web上的内容,使它变成自己知识库的一部分,同时也可以学习在过往几十年内人类选手在同样的智力问答节目中的表现,和正确答案、错误答案。从过去的事例中学习到经验,从而帮助提高他回答问题的准确度和自信度。
所以这给我们提供了一个窗口,让我们怎么样理解、怎么样应用这个大数据。可以分享一下我们学到了什么。《危险边缘》这样的一个挑战使得我们在开始确定研究方向和系统的架构之前做过一些分析。这一类的数据有什么样的特点,我们指的问题是用来回答问题的知识源,还有过去的问题。我们首先把问题拿来看了一下。这个问题过往几十年积累了几十万个问题,我们从中挑了两万个问题做类型的分析,把问题都会有期望的大安的问题,期望回答的答案是人或者是动物或者是地点、时间。这个类型往往可以通过问题点重点来标志。可以观察到这个图,这是一个很典型的长尾的现象,最频繁出现的问题的类型,在整个问题中出现的频度。我们传统的方法是能不能建数据库,把这个问题翻译成查询。我们看这是不可能的事情,我们不可能把世界上所有的事物都给它在数据库里建一条记录,这是不可能的事情。